长亭产研发对于雷池 WAF 的人机识别设计思考
摘要 人机识别是现代网站应用安全的重要保障手段之一,通过区分用户中的人类与机器人,将应用资源优先提供给人类用户,不仅能够优化资源配置,还能保护应用避免恶意机器人的危害。雷池 WAF(简称:雷池) 作为网站应用防火墙,识别出用户是人类还是机器人,对防护效果有很大帮助。雷池从自身定位出发,选了非侵入式的、在线的、渐进式的、问题解答式的人机识别方案。非侵入式表示雷池不会侵入业务,不需要业务进行任何功能的引入或集成;在线的表示雷池的人机识别需要用户能够访问在线服务(针对离线用户需要配合离线人机验证服务,这需要用户单独部署);渐进式表示雷池会分为两个阶段进行人机验证,第一个阶段认为当前用户为人类用户则通过,如果疑似机器人则进行第二阶段的问题解答;问题解答表示雷池会给用户“出一道题”,答对了就是人类,错误就是机器人。并且在人类用户识别的问题解答上,采用了一种创新的旋转图片拼接问题方式。
人机识别简述
在 2000 年,卡耐基大学的 Luis von Ahn 和 Manuel Blum 创建了一个工具,用来保护网站避免被机器人和垃圾邮件骚扰,起名叫做 Completely Automated Public Turing Test To Tell Computers and Humans Apart 简称 CAPTCHA。最初 CAPTCHA 的功能是生成一张图片,包含几个很扭曲的随机字符(如图),用户在访问网站前,需要识别并输入这几个字母。


这在当时是一个图灵问题,因为机器人能力有限,无法识别图片,能够识别出字符的就代表访问者是人类用户。 CAPTCHA 技术出现后,von Ahn 创建了 reCAPTCHA 项目用于推广该方案。但在 CAPTCHA 的实践中,有的对文字做了简单的模糊,有的直接使用未加工文字,有的则需要进行简单的计算,比如 “ 1 + 1 = ?”,这些问题过于简单,很容易被机器人破解。而 reCAPTCHA 项目则坚持原始的扭曲文字方案,并且会在图片上叠加混淆图层来提高识别难度。2009 年谷歌获得了 reCAPTCHA项目(谷歌利用该项目,识别了大量图片内容,间接积累了日后用于深度学习的训练数据),下面是谷歌对于 reCAPTCHA 的定义
What is reCAPTCHA?
reCAPTCHA is a free service from Google that helps protect websites from spam and abuse. A “CAPTCHA” is a turing test to tell human and bots apart. It is easy for humans to solve, but hard for “bots” and other malicious software to figure out. By adding reCAPTCHA to a site, you can block automated software while helping your welcome users to enter with ease.其本质是一个图灵测试过程,核心是构造一个问题,具有明显的不对称算力要求:对人很简单,对机器人很难。在谷歌的加持下,reCAPTCHA 项目的市占率持续超过 50%,很大程度上,它的发展影响着 CAPTCHA 技术的发展。目前,reCAPTCHA 发展到了 v3 版本:
| 版本 | 发布时间 | 识别方法 | 用户体验 |
|---|---|---|---|
| v1 | 2009 年 | 图片识别 | 按要求识别图片内容 |
| v2 | 2014 年 | 勾选框 |  |
| v3 | 2018 年 | 隐形分析 | (无感) |
经过 3 次大升级,reCAPTCHA 已经非常成熟,v3 版本已经做到用户无感知识别。不过 reCAPTCHA 并非无懈可击,已经有产品可以破解人机识别。其实不止 reCAPTCHA,其它主要人机识别服务亦无幸免(如图)。

那么如何防止人机识别被破解,最终又回到了它的本质:图灵问题。reCAPTCHA 在使用过程还有一个问题,必须 侵入式集成,网络应用必须引入 reCAPTCHA 的 sdk 才能使用。这对于要求无感的服务集成是非常致命的。
雷池 Waf 的人机识别
雷池是网络应用防火墙(Waf),需要预防各种网络威胁,机器人访问无论是否携带恶意代码,对 web 应用都是一种潜在威胁,识别出流量中的机器人用户也是 waf 的必备功能之一。雷池的人机识别设计方案,按照的功能的先后顺序,逐个分析解决下面的问题:
- 集成方式
- 验证方式
- 误判方案
- 图灵问题
集成方式
最佳实践中 waf 应该是让 web 应用完全无感,这样可以提供最好的兼容性,只要是符合 HTTP 协议的 web 应用就都可以代理并实施保护。根据是否侵入 web 应用,可以将集成方式分为 侵入式 和 非侵入式 两种,下面列出了两种方式的部分差别
| 侵入式 | 非侵入 | |
|---|---|---|
| 集成方法 | 网页中添加 sdk.js | 拦截请求验证 |
| 是否需要修改 web 应用 | 是 | 否 |
| 是否可以保护 API | 否 | 是 |
| 是否修改 cookie | 否 | 是 |
通过对比,雷池 waf 在选择了便于与 web 应用集成的 非侵入式 集成方案。主要原因一个是不用在 web 应用中集成 sdk,另一个则是可以保护 API。在网页中集成 sdk.js 虽然可以做到无感识别,但它只能在网页中生效,如果机器人跳过网页,直接访问 API 接口,像谷歌的 reCAPTCHA 是无法防护的。
对 API 的防护会导致一个副作用,在 SPA(单页面应用)下,用户会在一个页面上保持不变,不刷新页面,只调用 API 接口。如果这是 API 接口被人机识别功能拦截,页面上会出现 “接口异常” 的报错,但用户无法及时得知具体原因。
确定了非侵入集成方式后,下一步是如何对请求进行验证。因为 waf 在网络中的位置是在 web 应用前面的,所以非侵入方式下,人机验证过程需要拦截请求进行验证。如果验证结果通过,则放行,不通过则拦截。
验证方式
人机验证是的流程越严格,结果就越准确,但用户体验也越糟糕。为了区分人类与机器人,可以从 3 个方面入手:
| 人类 | 机器人 | 检查方法 | 关联请求数量 | |
|---|---|---|---|---|
| 运行环境不同 | 浏览器 | 脚本、模拟环境、无头浏览器 | JavaScript 检查器 | 一次 |
| 能力不同 | 图像识别能力强 | 图像识别能力有限 | 图片识别问题 | 一次 |
| 行为特征不同 | 访问速度慢,不符合随机性 | 访问速度快,符合随机性 | 流量特征统计 | 多次 |
-
运行环境
检查客户端是否具有一个普通浏览器的特征,例如客户端是否能够创建一个 iframe ,然后通过 postMessage 与 iframe 通信
-
用户能力
是否能解答一个图灵问题,比如听一段录音问题,能解答的是人类用户,不能解答就是机器人用户
-
行为特征
人类用户访问网站有目的性,访问路径(页面的跳转路径)也就具有规律性,而机器人则是漫无目的的爬数据,符合离散的均匀分布
机器人爬虫识别与防护(反爬)的思路基本上围绕这三个方面展开,特定业务场景下会加强特定方向的检查能力。其中 行为特征 与业务场景关联度非常高,比如电商网站,我想让自己的价格保密,但又想知道竞争对手的产品价格是多少?而竞争对手也是这么想的。这样,电商网站之间就会围绕产品 SKU 信息进行爬取和反爬竞争。
雷池 waf 的目标是通用网站服务,因此不会添加特定的业务流量检查模型。所以雷池 waf 的验证方式更加强调 运行环境 和 用户能力。为了兼顾准确率和用户体验,雷池采用了二段式验证的方法:先进行 运行环境 检测,如果为发现一点,则通过验证;如果疑似机器人(可能是误判,也可能是特殊浏览器,也可能是机器人),则需要再进行一次 用户能力 检测,通过一个图灵问题来判断当前是为为机器人。因为需要提供图灵问题,所以需要一个单独的人机验证服务来提供素材以及验证答案。而一般情况下 waf 只能代理业务服务,自身不能包含服务(因为会占用端口,暴露攻击面),这也是雷池 Waf 选择了云服务来提供人机验证服务的原因。
将上述的设计思路总结为流程,人机验证一共分为以下几个阶段:
| 阶段 | 动作 | 状态 | 结果 |
|---|---|---|---|
| 请求 | 是否包含人机 cookie | 包含 不包含 |
通过验证,结束 引导去人机页面 |
| 进入人机页面 | 检查执行环境 | 人类用户置信度高 疑似机器人 |
通过验证,设置 cookie 发起图灵问题挑战 |
| 图片识别 | 识别图片内容 | 识别成功 识别失败 |
通过验证,设置 cookie 拦截请求 |
完整人机验证流程


效果演示
下面来实际演示雷池人机验证效果,并做功能的分步解释
演示
将下面文件保存成 demo.html 文件,然后用浏览器打开,可以测试人机识别的效果。
<!DOCTYPE html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width" />
<script src="https://challenge.rivers.chaitin.cn/recaptcha/api/sdk.js"></script>
</head>
<body>
<script>
$Recap
.create({
once_id: "test",
image_type: 2,
force: true,
entrypoint: "https://challenge.rivers.chaitin.cn/recaptcha/api",
})
.run();
</script>
</body>
分步解释
雷池 waf 在开启人机识别功能后,对每个 HTTP 请求都会校验是否包含人机验证 cookie ,每个 cookie 都对应一个人机有效期,在有效期内则通过,不在有效期内则直接返回人机拦截页面(类似上面的 demo.html 文件内容)。
- 页面加载后,会从云服务加载 sdk.js
sdk.js 是深度混淆过的代码,这是为了防止暴露环境检查项,一旦暴露就会被针对,环境检查也就失去了效果。如果机器人不针对检查项,而是直接模拟一个完美浏览器环境,则会大大增加机器人的成本。所以人机识别 sdk.js 都是 不开源 的,开源既失效。
如果用户当前网络无法访问 sdk.js,那么人机验证就无法执行下去。需要提前确认用户与人机服务的连通性。
- 环境检查结果
在环境检查项的选择上,我们使用了比较传统的方法:浏览器特定能力检查,根据浏览器的类型来检查是否具备特定功能。除了特定能力外,还有新的 AI 检测方法,比如利用机器学习来对鼠标轨迹进行识别,判断人类与机器人。但根据我们的调研,AI 在人机识别的场景下能力非常有限。还是以鼠标轨迹识别为例,在手机或平板电脑设备上没有鼠标的时候,就无法使用,即使在 PC 上 AI 的识别率也不准确。
搜索 “AI 鼠标轨迹识别”、“AI 爬虫行为识别” 等关键字的论文,查看论文影响因子,就知道这种方法有多水。实际上 AI 的效果只在特定条件下的某个环节才有奇效。
为了隐藏检查项目和检查结果,sdk.js 会把环境检查结果加密上报给云服务。这样做的好处是,只要更新云服务就可以实现人机识别的整体功能升级,避免了 sdk 分发的缓慢升级过程。但这样做可能给用户带来一个疑虑:雷池 waf 会不会偷偷搜集用户数据?不会,三个理由:首先是雷池的免费服务算力少,无持久化存储;其次是人机识别页面与用户页面是分开的,无法统计数据;最后是雷池 waf 的品牌信誉,我们不搜集与人机识别无关的信息。
- 疑似爬虫
如果在环境检查后,当前用户为人类用户的置信度较低时,会提示检测失败,但为了防止误判,会给用户一个“申诉”的机会。sdk.js 会在环境检查为爬虫后,会发起一次图灵问题,雷池 waf 的人机识别更新到了 v2 版本,目前使用“旋转对齐图片”问题作为人机识别的核心问题。


- 结果判断
经过图片识别问题后,人机验证云服务会生成一个 jwt 返回给 sdk.js,再本地写入 cookie 后再刷新页面。此时,刷新后的页面会带上刚刚得到的人机验证加过 jwt 再次来到雷池 waf。雷池 waf 会验证 jwt 是否正确,如果正确,则放行当前请求,并用一个 session 替换掉 jwt。到此,人机验证完成。在当前的 session 内,用户的都被标记已通过人机验证。
统计数据
经过一段时间的试运行,雷池 waf 的人机识别已经正式发布,下面节选了某个服务实例 24h 的统计数据。
实测数据中请求人机识别数据

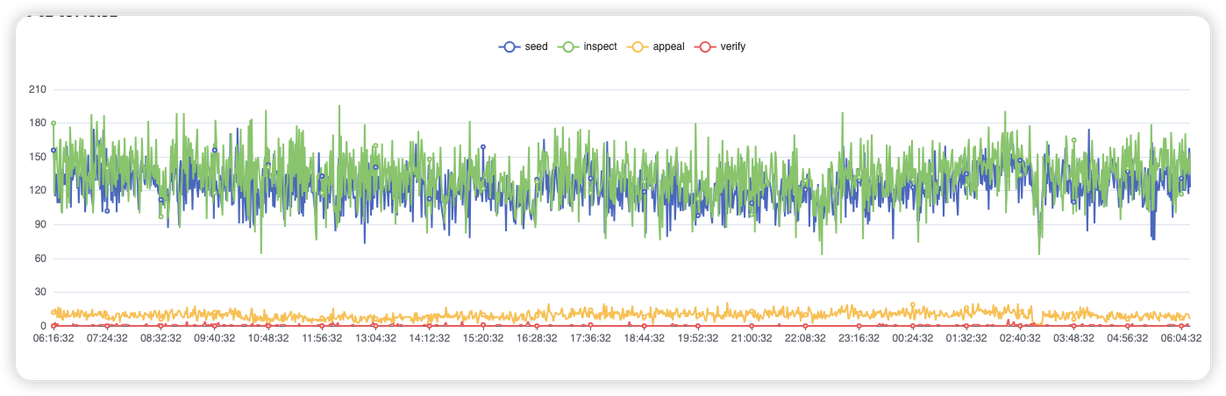
节选其中某个时刻的数据


我们来估算一下机器人用户的比例是多少?可以看到从环境检查(inspect)到图灵问题挑战(appeal)的转化率是 ~10%,从挑战(appeal)再到验证答案(verify)的转化率也是 ~10%。也就是所有被保护请求中约 10% 疑似人机,其中约 1% 通过验证是人类用户,也就是大约 9% 的访问量来自机器人,并被成功拦截。从统计结果来看,机器人的流量是超出了我们最初预期的(十分之一是爬虫),同是也证明了雷池 waf 的人机验证是有效的。
总结
人机验证是网络应用安全的重要环节,通过回顾 CAPTCHA 的发展来总结机器人识别的技术特征。根据雷池 waf 的业务场景选择了 非侵入式 集成的 云服务 人机识别功能,为了完善图灵问题,雷池 waf 还改善了图片识别的方法(已申请专利)。通过一段时间的云服务测试,证明雷池的人机方案思路是可行的。机器人识别和反识别是一对儿矛和盾的关系,双方都在成长,雷池 waf 的人机识别也还有很大进步空间,如果利用好 云服务 + 本地流量入口的天然优势,雷池的人机识别功能可以实现其他集成服务无法实现的能力。
产品创新团队 王德龙