【洞鉴】X-Ray 安全评估系统 主动爬虫与目录探测
一个漏洞会被主动扫描检出,检出的这些URL 首先会经历两个步骤
1: 爬取
2:目录探测与遍历
在确认站点存活的情况下,爬虫会对扫描目标的根目录,进行指纹探测,尝试识别服务类型,同时,如果开启的是浏览器爬虫,爬虫会同时对页面的表单与链接、以及执行其中的JS(注:JS中的相关路径洞鉴也会尝试探测)
扫描结束后,爬虫爬取到的网站目录,可以在WEB站点详情中查看


爬虫的探测受到参数限制,其中,
最大爬取深度不是URLpath的深度,控制的是扫描目标扫描层级。是多少次点击可以到达此path。如果一次点击就能到达,则深度为1,此值默认为5,代表着爬虫最多能爬取到点击5次后到达的页面,超过此数量,爬虫不会爬取

如果网页深度较深,建议酌情调高此值(注:会延长扫描时间)
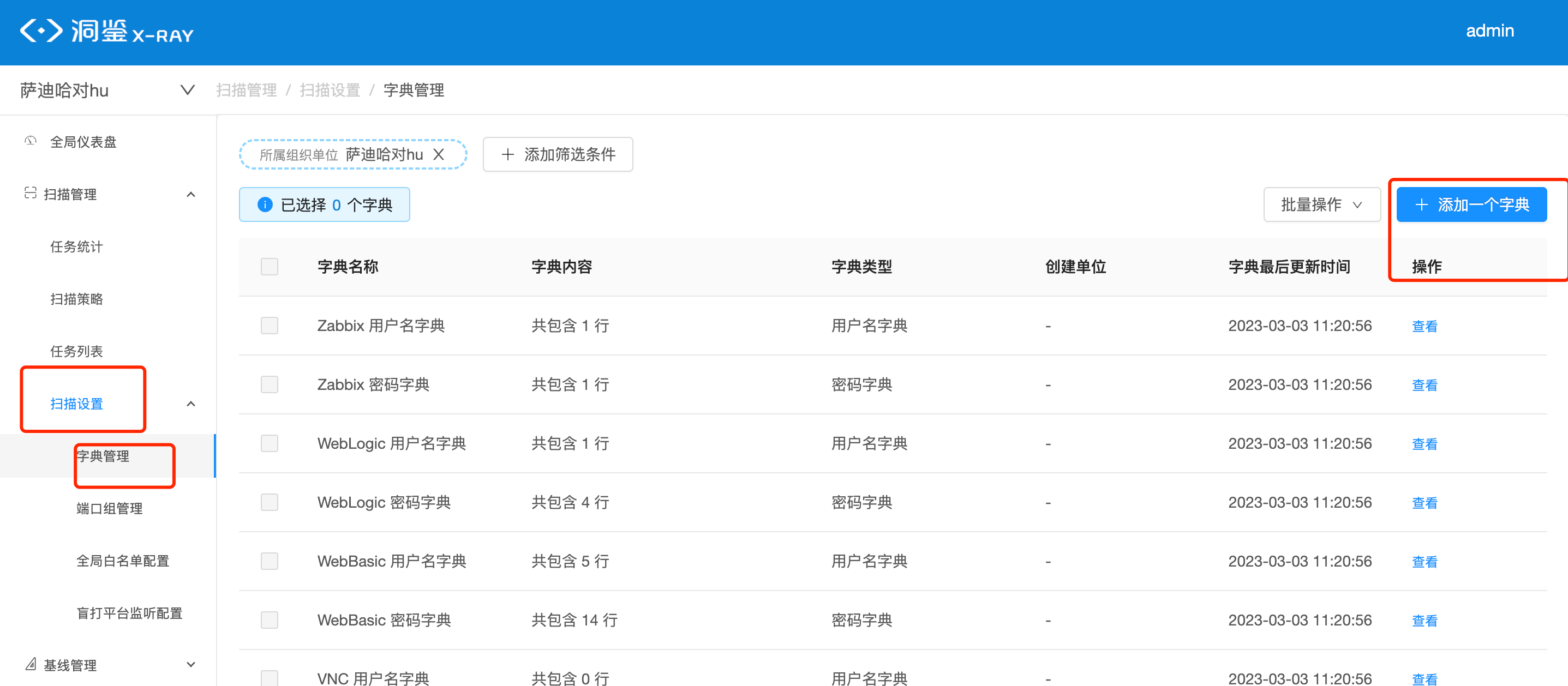
如果通过爬取爬取不到(即没有链接能访问到网页),则我们会通过目录探测的方式进行扫描,扫描的具体内容,可以在字典信息中查看

如果一个网页,他既不能被爬虫点击到,也不在内置的目录字典中,则他不会被洞鉴识别,也不会被扫描到
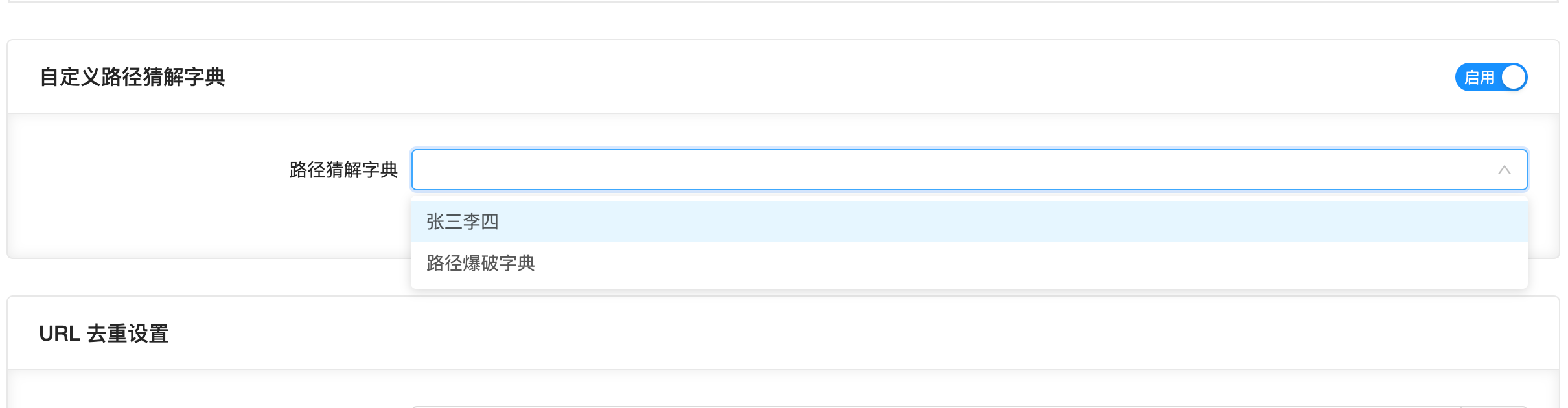
如果您这边有特殊的目录,希望被爬虫扫描到,可以在上图的页面自定义目录字典,然后在任务中选用
注:如果使用了自定义目录字典,则内置路径字典不会生效,请注意